
South China Geographical Journal >
Recent Advances in Bayesian Spatial Econometric Models: Assessing Estimation Accuracy and Computational Efficiency
Received date: 2025-01-03
Revised date: 2025-03-05
Online published: 2025-06-18
Spatial econometric models can be used to capture spatial dependence within data. These models have found extensive application in disciplines such as economics, management and network analyses. Bayesian methods, such as Markov Chain Monte Carlo algorithms, have addressed many limitations of classical approaches, hence significantly advancing both theoretical and applied research. With the growing availability of large datasets and advancements in computational methods, Bayesian estimation methods are required not only to provide accurate estimates but also to balance computational efficiency. This study examines three state-of-the-art Bayesian methods, i.e., Hamiltonian Monte Carlo (HMC), Integrated Nested Laplace Approximations (INLA), and Variational Inference (VI). Various Monte Carlo simulation experiments were conducted to evaluate the performance of them under different sample sizes and key parameters. The results demonstrate that all three methods exhibit good performance. HMC excels for small sample sizes, whereas INLA demonstrates superior computational efficiency for large datasets. The VI method serves as an effective complement to the first two methods. This study provides theoretical guidance for researchers applying Bayesian techniques to spatial econometric models and practical insights for empirical analysts selecting suitable estimation methods based on computational constraints.
LING Yuheng , MA Donglai , GUI Yu . Recent Advances in Bayesian Spatial Econometric Models: Assessing Estimation Accuracy and Computational Efficiency[J]. South China Geographical Journal, 2025 , 3(1) : 24 -37 . DOI: 10.20125/j.2097-2245.202501002
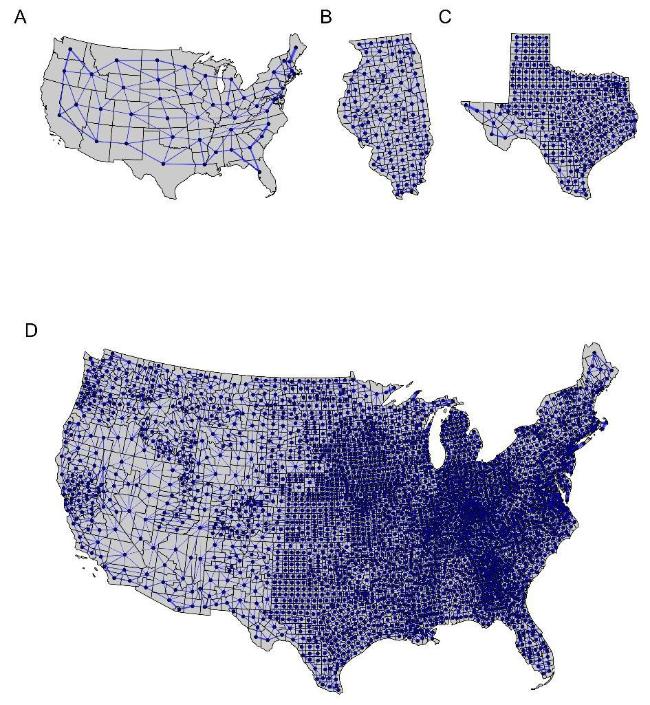
图1 4种不同空间结构(A、B、C、D)中基于“车”准则的空间临近关系示意图,样本量依次从小到大排列Fig.1 A schematic diagram of spatial proximity based on the 'rook' criterion in four different spatial structures (A, B, C, D) in the simulation |
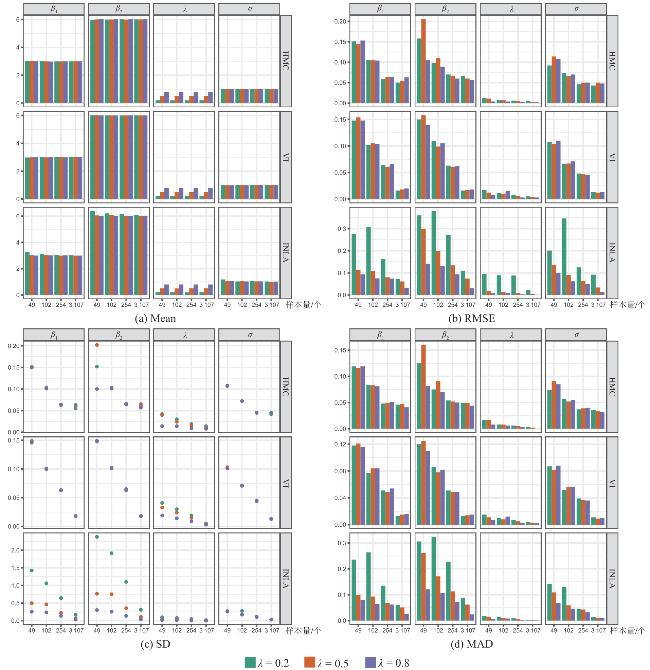
表1 样本量 的情况下HMC、VI、INLA对空间滞后模型的模拟结果Tab.1 Simulation results for SLM using HMC, VI, and INLA across different sample sizes |
| 估计方法 | 参数真实值 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | RMSE | RRMSE | MAD | Mean | SD | RMSE | RRMSE | MAD | Mean | SD | RMSE | RRMSE | MAD | Mean | SD | RMSE | RRMSE | MAD | ||
| HMC | 0.201 | 0.042 | 0.012 | 0.062 | 0.017 | 0.200 | 0.030 | 0.008 | 0.038 | 0.008 | 0.200 | 0.019 | 0.006 | 0.029 | 0.006 | 0.200 | 0.014 | 0.005 | 0.027 | 0.003 | |
| 1.010 | 0.108 | 0.092 | 0.092 | 0.074 | 0.996 | 0.072 | 0.073 | 0.073 | 0.057 | 1.003 | 0.045 | 0.046 | 0.046 | 0.037 | 1.001 | 0.042 | 0.043 | 0.043 | 0.036 | ||
| 3.020 | 0.150 | 0.151 | 0.050 | 0.119 | 3.001 | 0.101 | 0.105 | 0.035 | 0.084 | 2.996 | 0.063 | 0.059 | 0.020 | 0.048 | 2.999 | 0.055 | 0.050 | 0.017 | 0.046 | ||
| 5.955 | 0.152 | 0.158 | 0.026 | 0.125 | 5.990 | 0.101 | 0.098 | 0.016 | 0.075 | 6.004 | 0.064 | 0.070 | 0.012 | 0.054 | 6.000 | 0.061 | 0.066 | 0.010 | 0.049 | ||
| 0.499 | 0.040 | 0.011 | 0.023 | 0.017 | 0.500 | 0.024 | 0.007 | 0.014 | 0.008 | 0.500 | 0.015 | 0.005 | 0.009 | 0.005 | 0.500 | 0.011 | 0.003 | 0.006 | 0.002 | ||
| 1.004 | 0.107 | 0.114 | 0.114 | 0.091 | 1.005 | 0.072 | 0.066 | 0.066 | 0.052 | 1.004 | 0.045 | 0.050 | 0.050 | 0.039 | 1.002 | 0.045 | 0.050 | 0.050 | 0.034 | ||
| 3.031 | 0.151 | 0.145 | 0.048 | 0.116 | 2.999 | 0.103 | 0.105 | 0.035 | 0.083 | 2.992 | 0.064 | 0.064 | 0.021 | 0.049 | 2.998 | 0.060 | 0.054 | 0.019 | 0.047 | ||
| 5.998 | 0.202 | 0.205 | 0.034 | 0.160 | 5.994 | 0.103 | 0.110 | 0.018 | 0.091 | 5.988 | 0.065 | 0.067 | 0.011 | 0.052 | 5.998 | 0.065 | 0.060 | 0.011 | 0.049 | ||
| 0.800 | 0.014 | 0.004 | 0.005 | 0.008 | 0.800 | 0.014 | 0.004 | 0.005 | 0.006 | 0.800 | 0.009 | 0.003 | 0.003 | 0.003 | 0.800 | 0.008 | 0.002 | 0.003 | 0.000 | ||
| 1.006 | 0.107 | 0.108 | 0.108 | 0.085 | 0.995 | 0.072 | 0.070 | 0.070 | 0.055 | 1.003 | 0.045 | 0.050 | 0.050 | 0.040 | 1.002 | 0.045 | 0.048 | 0.048 | 0.032 | ||
| 3.002 | 0.150 | 0.153 | 0.051 | 0.119 | 2.978 | 0.102 | 0.104 | 0.035 | 0.081 | 3.002 | 0.064 | 0.064 | 0.021 | 0.051 | 3.000 | 0.063 | 0.063 | 0.019 | 0.041 | ||
| 6.009 | 0.100 | 0.105 | 0.017 | 0.082 | 6.007 | 0.102 | 0.089 | 0.015 | 0.070 | 6.010 | 0.066 | 0.060 | 0.010 | 0.050 | 6.007 | 0.057 | 0.057 | 0.009 | 0.044 | ||
| VI | 0.200 | 0.041 | 0.017 | 0.086 | 0.015 | 0.200 | 0.030 | 0.011 | 0.057 | 0.010 | 0.200 | 0.019 | 0.008 | 0.038 | 0.007 | 0.200 | 0.005 | 0.005 | 0.027 | 0.004 | |
| 0.996 | 0.103 | 0.107 | 0.107 | 0.087 | 1.002 | 0.071 | 0.066 | 0.066 | 0.052 | 0.996 | 0.044 | 0.048 | 0.048 | 0.039 | 1.000 | 0.013 | 0.013 | 0.013 | 0.011 | ||
| 2.980 | 0.149 | 0.148 | 0.049 | 0.118 | 2.997 | 0.101 | 0.102 | 0.034 | 0.077 | 3.010 | 0.063 | 0.064 | 0.021 | 0.051 | 3.000 | 0.018 | 0.016 | 0.005 | 0.013 | ||
| 6.010 | 0.149 | 0.150 | 0.025 | 0.120 | 6.002 | 0.101 | 0.109 | 0.018 | 0.086 | 6.001 | 0.063 | 0.063 | 0.010 | 0.051 | 6.003 | 0.018 | 0.016 | 0.003 | 0.013 | ||
| 0.499 | 0.033 | 0.012 | 0.024 | 0.011 | 0.500 | 0.024 | 0.010 | 0.020 | 0.008 | 0.500 | 0.015 | 0.006 | 0.012 | 0.005 | 0.500 | 0.004 | 0.004 | 0.008 | 0.003 | ||
| 0.989 | 0.103 | 0.104 | 0.104 | 0.082 | 0.997 | 0.071 | 0.067 | 0.067 | 0.056 | 1.000 | 0.045 | 0.047 | 0.047 | 0.037 | 0.999 | 0.013 | 0.012 | 0.012 | 0.009 | ||
| 2.995 | 0.148 | 0.154 | 0.051 | 0.121 | 2.995 | 0.100 | 0.105 | 0.035 | 0.084 | 3.001 | 0.063 | 0.061 | 0.020 | 0.049 | 3.001 | 0.018 | 0.018 | 0.006 | 0.015 | ||
| 6.014 | 0.148 | 0.158 | 0.026 | 0.125 | 6.000 | 0.102 | 0.099 | 0.016 | 0.078 | 6.001 | 0.064 | 0.061 | 0.010 | 0.049 | 6.002 | 0.018 | 0.017 | 0.003 | 0.014 | ||
| 0.799 | 0.019 | 0.008 | 0.010 | 0.007 | 0.798 | 0.014 | 0.015 | 0.019 | 0.012 | 0.800 | 0.009 | 0.003 | 0.004 | 0.003 | 0.800 | 0.003 | 0.003 | 0.003 | 0.002 | ||
| 0.988 | 0.101 | 0.110 | 0.110 | 0.088 | 0.995 | 0.071 | 0.071 | 0.071 | 0.056 | 1.000 | 0.045 | 0.045 | 0.045 | 0.036 | 1.002 | 0.013 | 0.013 | 0.013 | 0.010 | ||
| 2.998 | 0.146 | 0.148 | 0.049 | 0.116 | 2.998 | 0.100 | 0.104 | 0.035 | 0.084 | 2.995 | 0.063 | 0.066 | 0.022 | 0.054 | 2.998 | 0.018 | 0.020 | 0.007 | 0.016 | ||
| 6.001 | 0.149 | 0.140 | 0.023 | 0.110 | 5.998 | 0.102 | 0.105 | 0.018 | 0.082 | 6.002 | 0.065 | 0.062 | 0.010 | 0.049 | 6.001 | 0.018 | 0.018 | 0.003 | 0.015 | ||
| INLA | 0.212 | 0.097 | 0.096 | 0.480 | 0.017 | 0.201 | 0.073 | 0.089 | 0.450 | 0.015 | 0.200 | 0.047 | 0.088 | 0.440 | 0.009 | 0.200 | 0.013 | 0.021 | 0.104 | 0.003 | |
| 1.180 | 0.274 | 0.201 | 0.201 | 0.142 | 1.031 | 0.279 | 0.346 | 0.346 | 0.130 | 1.073 | 0.111 | 0.125 | 0.125 | 0.045 | 1.024 | 0.033 | 0.092 | 0.092 | 0.015 | ||
| 3.264 | 1.423 | 0.275 | 0.092 | 0.236 | 3.144 | 1.061 | 0.307 | 0.102 | 0.264 | 3.058 | 0.644 | 0.162 | 0.054 | 0.135 | 3.015 | 0.168 | 0.073 | 0.024 | 0.060 | ||
| 6.379 | 2.380 | 0.360 | 0.060 | 0.306 | 6.210 | 1.914 | 0.379 | 0.063 | 0.324 | 6.177 | 1.101 | 0.272 | 0.045 | 0.228 | 6.091 | 0.308 | 0.110 | 0.018 | 0.086 | ||
| 0.502 | 0.043 | 0.018 | 0.035 | 0.015 | 0.498 | 0.044 | 0.013 | 0.026 | 0.011 | 0.501 | 0.021 | 0.009 | 0.017 | 0.007 | 0.501 | 0.007 | 0.004 | 0.008 | 0.003 | ||
| 1.057 | 0.262 | 0.136 | 0.136 | 0.109 | 1.055 | 0.175 | 0.091 | 0.091 | 0.059 | 1.033 | 0.106 | 0.063 | 0.063 | 0.043 | 1.003 | 0.032 | 0.034 | 0.034 | 0.011 | ||
| 3.020 | 0.496 | 0.114 | 0.038 | 0.099 | 3.036 | 0.463 | 0.108 | 0.036 | 0.093 | 2.996 | 0.221 | 0.080 | 0.027 | 0.068 | 2.996 | 0.073 | 0.061 | 0.020 | 0.051 | ||
| 6.055 | 0.765 | 0.298 | 0.050 | 0.261 | 6.081 | 0.752 | 0.198 | 0.033 | 0.171 | 6.001 | 0.356 | 0.134 | 0.022 | 0.113 | 5.987 | 0.108 | 0.074 | 0.012 | 0.062 | ||
| 0.800 | 0.016 | 0.008 | 0.010 | 0.006 | 0.801 | 0.017 | 0.010 | 0.012 | 0.008 | 0.800 | 0.007 | 0.003 | 0.004 | 0.003 | 0.800 | 0.002 | 0.001 | 0.001 | 0.001 | ||
| 1.056 | 0.262 | 0.100 | 0.100 | 0.068 | 1.030 | 0.170 | 0.062 | 0.062 | 0.046 | 1.032 | 0.106 | 0.050 | 0.050 | 0.032 | 1.013 | 0.033 | 0.014 | 0.014 | 0.011 | ||
| 2.999 | 0.256 | 0.093 | 0.031 | 0.080 | 3.009 | 0.236 | 0.075 | 0.025 | 0.064 | 3.009 | 0.138 | 0.074 | 0.025 | 0.062 | 2.997 | 0.036 | 0.033 | 0.011 | 0.026 | ||
| 6.008 | 0.302 | 0.141 | 0.023 | 0.121 | 5.991 | 0.253 | 0.131 | 0.022 | 0.106 | 5.997 | 0.136 | 0.093 | 0.016 | 0.073 | 5.996 | 0.038 | 0.030 | 0.005 | 0.024 | ||
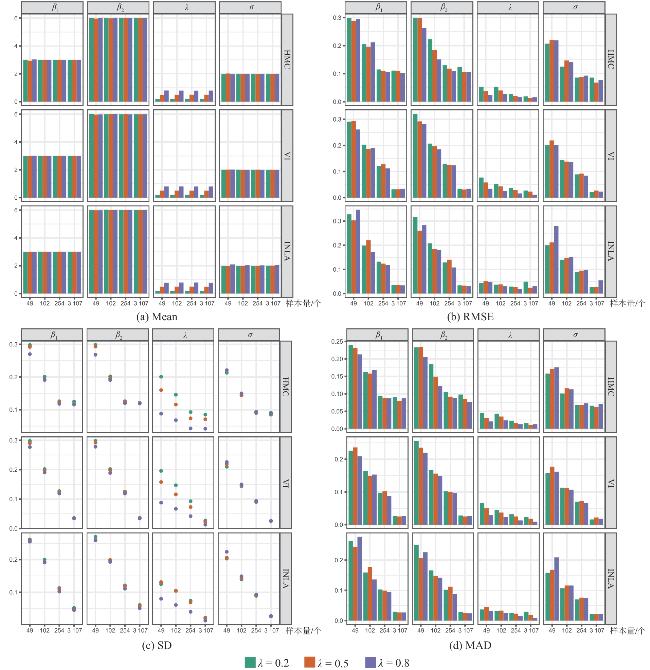
表2 样本量 的情况下HMC、VI、INLA对空间误差模型的模拟结果Tab.2 Simulation results for SEM using HMC, VI, and INLA across different sample sizes |
| 估计方法 | 参数真实值 | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | RMSE | RRMSE | MAD | Mean | SD | RMSE | RRMSE | MAD | Mean | SD | RMSE | RRMSE | MAD | Mean | SD | RMSE | RRMSE | MAD | ||
| HMC | 0.199 | 0.201 | 0.053 | 0.272 | 0.045 | 0.204 | 0.146 | 0.053 | 0.268 | 0.043 | 0.204 | 0.093 | 0.027 | 0.134 | 0.023 | 0.201 | 0.085 | 0.019 | 0.098 | 0.016 | |
| 2.007 | 0.213 | 0.207 | 0.104 | 0.158 | 2.004 | 0.144 | 0.125 | 0.063 | 0.101 | 2.004 | 0.090 | 0.086 | 0.043 | 0.068 | 2.002 | 0.085 | 0.086 | 0.040 | 0.066 | ||
| 3.007 | 0.298 | 0.298 | 0.099 | 0.240 | 3.002 | 0.201 | 0.205 | 0.068 | 0.162 | 3.001 | 0.126 | 0.115 | 0.038 | 0.094 | 3.002 | 0.125 | 0.111 | 0.037 | 0.090 | ||
| 6.007 | 0.298 | 0.299 | 0.050 | 0.233 | 6.010 | 0.202 | 0.223 | 0.037 | 0.185 | 6.007 | 0.126 | 0.13 | 0.022 | 0.105 | 6.005 | 0.121 | 0.124 | 0.019 | 0.098 | ||
| 0.495 | 0.160 | 0.037 | 0.073 | 0.031 | 0.501 | 0.116 | 0.040 | 0.082 | 0.035 | 0.502 | 0.074 | 0.020 | 0.040 | 0.016 | 0.501 | 0.071 | 0.013 | 0.028 | 0.011 | ||
| 2.024 | 0.220 | 0.221 | 0.110 | 0.171 | 1.985 | 0.145 | 0.147 | 0.074 | 0.116 | 2.005 | 0.092 | 0.088 | 0.044 | 0.068 | 2.002 | 0.090 | 0.068 | 0.034 | 0.062 | ||
| 2.945 | 0.292 | 0.288 | 0.096 | 0.231 | 2.995 | 0.193 | 0.196 | 0.065 | 0.158 | 2.998 | 0.123 | 0.110 | 0.037 | 0.088 | 2.999 | 0.117 | 0.110 | 0.031 | 0.080 | ||
| 5.968 | 0.293 | 0.298 | 0.050 | 0.234 | 5.982 | 0.196 | 0.184 | 0.031 | 0.149 | 6.012 | 0.124 | 0.118 | 0.020 | 0.092 | 6.010 | 0.121 | 0.106 | 0.018 | 0.086 | ||
| 0.803 | 0.088 | 0.024 | 0.032 | 0.021 | 0.798 | 0.068 | 0.028 | 0.034 | 0.024 | 0.796 | 0.043 | 0.016 | 0.019 | 0.013 | 0.798 | 0.042 | 0.016 | 0.018 | 0.013 | ||
| 1.969 | 0.221 | 0.219 | 0.110 | 0.176 | 2.009 | 0.150 | 0.141 | 0.070 | 0.113 | 1.993 | 0.094 | 0.093 | 0.046 | 0.073 | 1.995 | 0.091 | 0.077 | 0.038 | 0.071 | ||
| 3.033 | 0.270 | 0.295 | 0.098 | 0.213 | 2.997 | 0.191 | 0.212 | 0.071 | 0.168 | 3.002 | 0.118 | 0.107 | 0.036 | 0.087 | 3.000 | 0.116 | 0.103 | 0.034 | 0.087 | ||
| 6.018 | 0.268 | 0.263 | 0.044 | 0.205 | 6.013 | 0.191 | 0.151 | 0.025 | 0.122 | 6.010 | 0.120 | 0.109 | 0.018 | 0.088 | 6.008 | 0.119 | 0.105 | 0.017 | 0.077 | ||
| VI | 0.197 | 0.196 | 0.077 | 0.392 | 0.066 | 0.199 | 0.147 | 0.053 | 0.269 | 0.045 | 0.203 | 0.093 | 0.037 | 0.185 | 0.032 | 0.198 | 0.027 | 0.027 | 0.137 | 0.023 | |
| 2.004 | 0.210 | 0.201 | 0.100 | 0.158 | 2.006 | 0.144 | 0.144 | 0.072 | 0.113 | 2.003 | 0.09 | 0.089 | 0.044 | 0.070 | 2.001 | 0.025 | 0.021 | 0.010 | 0.016 | ||
| 2.996 | 0.298 | 0.291 | 0.097 | 0.226 | 3.002 | 0.202 | 0.203 | 0.068 | 0.164 | 2.999 | 0.127 | 0.121 | 0.040 | 0.097 | 3.001 | 0.036 | 0.032 | 0.011 | 0.027 | ||
| 6.028 | 0.298 | 0.321 | 0.054 | 0.256 | 6.000 | 0.202 | 0.207 | 0.034 | 0.167 | 5.994 | 0.126 | 0.129 | 0.022 | 0.102 | 5.999 | 0.036 | 0.034 | 0.006 | 0.028 | ||
| 0.502 | 0.158 | 0.058 | 0.119 | 0.050 | 0.502 | 0.116 | 0.043 | 0.087 | 0.037 | 0.501 | 0.073 | 0.029 | 0.058 | 0.025 | 0.499 | 0.022 | 0.023 | 0.046 | 0.018 | ||
| 2.013 | 0.219 | 0.219 | 0.109 | 0.177 | 2.005 | 0.147 | 0.138 | 0.069 | 0.111 | 2.009 | 0.092 | 0.092 | 0.046 | 0.072 | 2.004 | 0.026 | 0.027 | 0.014 | 0.022 | ||
| 2.986 | 0.290 | 0.294 | 0.098 | 0.236 | 3.004 | 0.197 | 0.187 | 0.062 | 0.149 | 3.001 | 0.124 | 0.128 | 0.043 | 0.102 | 3.002 | 0.035 | 0.032 | 0.011 | 0.025 | ||
| 5.971 | 0.292 | 0.292 | 0.049 | 0.235 | 6.003 | 0.198 | 0.197 | 0.033 | 0.156 | 6.003 | 0.124 | 0.126 | 0.021 | 0.100 | 5.996 | 0.035 | 0.031 | 0.005 | 0.025 | ||
| 0.801 | 0.088 | 0.034 | 0.043 | 0.029 | 0.802 | 0.067 | 0.026 | 0.033 | 0.023 | 0.800 | 0.042 | 0.016 | 0.020 | 0.013 | 0.800 | 0.013 | 0.011 | 0.014 | 0.009 | ||
| 2.012 | 0.226 | 0.201 | 0.101 | 0.162 | 2.001 | 0.150 | 0.136 | 0.068 | 0.107 | 1.997 | 0.094 | 0.084 | 0.042 | 0.066 | 2.001 | 0.026 | 0.023 | 0.011 | 0.018 | ||
| 3.009 | 0.277 | 0.261 | 0.087 | 0.209 | 2.991 | 0.191 | 0.191 | 0.064 | 0.153 | 3.005 | 0.119 | 0.112 | 0.037 | 0.088 | 2.999 | 0.034 | 0.034 | 0.011 | 0.026 | ||
| 5.985 | 0.278 | 0.282 | 0.047 | 0.220 | 6.008 | 0.189 | 0.185 | 0.031 | 0.149 | 5.991 | 0.119 | 0.124 | 0.021 | 0.097 | 5.996 | 0.034 | 0.034 | 0.006 | 0.027 | ||
| INLA | 0.204 | 0.125 | 0.043 | 0.215 | 0.037 | 0.201 | 0.105 | 0.037 | 0.187 | 0.032 | 0.201 | 0.074 | 0.029 | 0.147 | 0.025 | 0.195 | 0.022 | 0.049 | 0.244 | 0.029 | |
| 1.967 | 0.203 | 0.200 | 0.100 | 0.158 | 1.973 | 0.139 | 0.140 | 0.070 | 0.107 | 1.992 | 0.089 | 0.089 | 0.045 | 0.070 | 1.999 | 0.026 | 0.027 | 0.013 | 0.021 | ||
| 2.981 | 0.262 | 0.328 | 0.109 | 0.263 | 3.009 | 0.200 | 0.199 | 0.066 | 0.159 | 2.997 | 0.113 | 0.132 | 0.044 | 0.103 | 3.001 | 0.052 | 0.035 | 0.012 | 0.029 | ||
| 6.003 | 0.270 | 0.317 | 0.053 | 0.251 | 6.025 | 0.199 | 0.208 | 0.035 | 0.166 | 5.996 | 0.121 | 0.129 | 0.022 | 0.102 | 6.003 | 0.061 | 0.034 | 0.006 | 0.028 | ||
| 0.498 | 0.131 | 0.051 | 0.103 | 0.045 | 0.500 | 0.104 | 0.038 | 0.077 | 0.033 | 0.501 | 0.069 | 0.027 | 0.054 | 0.023 | 0.493 | 0.02 | 0.024 | 0.047 | 0.019 | ||
| 1.966 | 0.206 | 0.212 | 0.106 | 0.168 | 1.991 | 0.143 | 0.147 | 0.073 | 0.116 | 1.993 | 0.090 | 0.095 | 0.048 | 0.076 | 2.006 | 0.026 | 0.027 | 0.013 | 0.021 | ||
| 2.996 | 0.258 | 0.303 | 0.101 | 0.244 | 3.002 | 0.192 | 0.221 | 0.074 | 0.177 | 3.006 | 0.109 | 0.124 | 0.041 | 0.099 | 3.001 | 0.045 | 0.035 | 0.012 | 0.027 | ||
| 5.986 | 0.261 | 0.260 | 0.043 | 0.207 | 6.000 | 0.199 | 0.184 | 0.031 | 0.147 | 5.994 | 0.119 | 0.140 | 0.023 | 0.112 | 6.002 | 0.058 | 0.033 | 0.005 | 0.025 | ||
| 0.775 | 0.080 | 0.047 | 0.058 | 0.032 | 0.794 | 0.061 | 0.030 | 0.037 | 0.025 | 0.795 | 0.040 | 0.019 | 0.023 | 0.015 | 0.772 | 0.013 | 0.030 | 0.037 | 0.008 | ||
| 2.096 | 0.224 | 0.280 | 0.140 | 0.209 | 2.034 | 0.149 | 0.152 | 0.076 | 0.116 | 2.026 | 0.093 | 0.098 | 0.049 | 0.075 | 2.047 | 0.027 | 0.055 | 0.027 | 0.022 | ||
| 2.977 | 0.255 | 0.347 | 0.116 | 0.277 | 2.993 | 0.191 | 0.172 | 0.057 | 0.136 | 3.003 | 0.102 | 0.118 | 0.039 | 0.094 | 3.001 | 0.048 | 0.034 | 0.011 | 0.027 | ||
| 5.988 | 0.259 | 0.283 | 0.047 | 0.226 | 5.995 | 0.193 | 0.181 | 0.030 | 0.142 | 6.009 | 0.111 | 0.108 | 0.018 | 0.087 | 6.004 | 0.051 | 0.030 | 0.005 | 0.024 | ||
1 Rook型与Queen型在模拟中的表现相近。
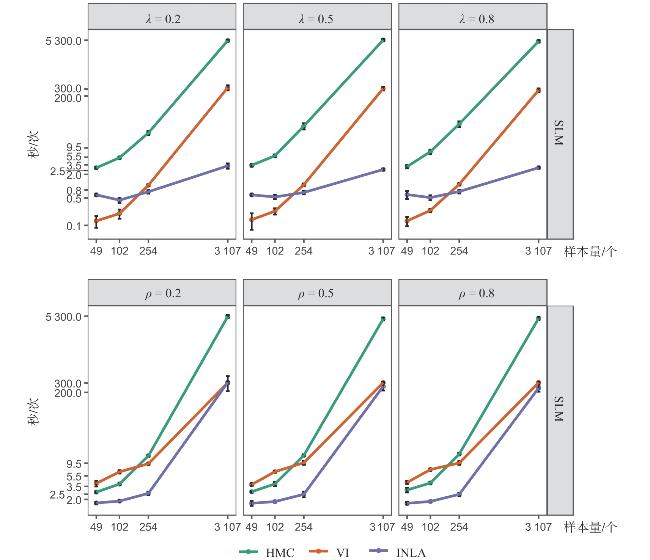
2 本文中的蒙特卡罗模拟实验均在R-4.2.2平台下完成。INLA方法使用R-INLA程序包;HMC与VI方法使用cmdstanr程序包。
3 图1和图2对应的原始表格已呈现在附件1中。
| 1 |
|
| 2 |
|
| 3 |
李军, 冼凡几, 何莽. 中国康养旅游发展潜力的时空演化格局及空间效应分析 [J]. 华南地理学报, 2023, 1(1): 78-91.
|
| 4 |
方远平, 肖亚儿, 宋雅玲, 等. 珠三角地区电子信息产业空间格局及影响因素——基于企业POI数据的分析 [J]. 华南地理学报, 2023, 1(2): 15-26.
|
| 5 |
粟娟, 刘蕾, 王艳. 武陵山片区乡村旅游对乡村经济发展的空间溢出效应研究 [J]. 华南地理学报, 2023, 1(3): 65-80.
|
| 6 |
|
| 7 |
|
| 8 |
|
| 9 |
|
| 10 |
|
| 11 |
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|
| 18 |
|
| 19 |
|
| 20 |
|
| 21 |
|
| 22 |
|
| 23 |
|
| 24 |
|
| 25 |
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 |
|
| 30 |
|
| 31 |
|
/
| 〈 |
|
〉 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}